The Cost of AI Compute: Google’s TPU Advantage vs. OpenAI’s Nvidia Tax

Sign up for ARPU: Stay informed with our newsletter - or upgrade to bespoke intelligence.
Earlier this month, Google’s DeepMind AI research unit unveiled Gemini 2.5 Pro “I/O” edition, quickly hailed by DeepMind CEO Demis Hassabis as “the best coding model we’ve ever built!” This new iteration of its Gemini 2.5 Pro has, for the first time in the generative AI race, reportedly dethroned rivals on key coding benchmarks.
This rapid advancement highlights not just Google’s innovative stride, but also the underlying economic advantage that enables it to deliver such cutting-edge performance at highly competitive prices.
What’s Google’s TPU Advantage?
The most significant, yet often under-discussed, advantage Google holds is its “secret weapon”: its decade-long investment in custom Tensor Processing Units (TPUs). Google designs and deploys its own TPUs, like the recently unveiled Ironwood generation, for its core AI workloads, including training and serving Gemini models.
This internal manufacturing strategy allows Google to bypass the hefty premiums associated with third-party hardware. Nvidia, on the other hand, commands staggering gross margins, estimated by analysts to be in the 80% range for data center chips like the H100 and upcoming B100 GPUs. This means hyperscalers like Microsoft (who supply OpenAI) pay a significant markup for their compute power. Industry analysis suggests that Google may be obtaining its AI compute power at roughly 20% of the cost incurred by those purchasing high-end Nvidia GPUs, implying a 4x-6x cost efficiency advantage per unit of compute at the hardware level.
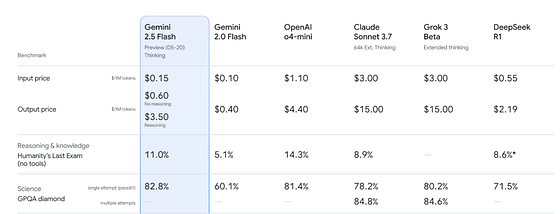
What’s the “Nvidia Tax” on OpenAI?
OpenAI and the broader market rely heavily on Nvidia’s powerful but expensive GPUs. While manufacturing these GPUs might cost Nvidia $3,000-$5,000, hyperscalers pay $20,000-$35,000+ per unit in volume. This cost burden, often dubbed the “Nvidia tax,” is a significant factor in OpenAI’s operational expenses.
Compute costs represent an estimated 55–60% of OpenAI’s total $9 billion operating expenses in 2024, according to industry reports. This figure is projected to exceed 80% in 2025 as their operations scale. Despite OpenAI’s projected astronomical revenue growth — potentially hitting $125 billion by 2029 — managing this compute spend remains a critical challenge, driving their pursuit of custom silicon or alternative infrastructure solutions like the Stargate Project.
How Does This Impact Pricing and Strategy?
This fundamental cost differential isn’t merely academic; it has profound strategic implications for both companies and their customers. Google can sustain lower prices and offer better “intelligence per dollar,” giving enterprises more predictable long-term Total Cost of Ownership (TCO).
This is reflected in their API pricing. Google’s Gemini 2.5 Pro is priced at $10 per 1 million output tokens (vs OpenAI o3’s $40 per 1 million output tokens). Its Gemini 2.5 Flash model is remarkably inexpensive at just 60 cents (non-thinking) / $3.5 (thinking model) per 1 million output tokens (vs o4 mini’s $4.40 per 1 million output tokens).
Google even offers Gemini 2.5 free for use through its Gemini app and AI Studio website, positioning itself as a price leader in the market.
This economic reality allows Google to aggressively price its services, potentially making it a more attractive long-term partner for enterprises looking to scale their AI deployments without incurring prohibitive costs.
What Does This Mean for the AI Race?
Google’s vertically integrated TPU strategy, allowing it to bypass the substantial “Nvidia Tax,” represents a fundamental economic advantage in the AI platform war. This impacts everything from API affordability and TCO predictability to the sheer scalability of AI deployments. As AI workloads grow exponentially, the platform with the more sustainable economic engine — fueled by hardware cost efficiency — holds a powerful strategic edge.
Meanwhile, OpenAI, backed by Microsoft’s distribution and market reach, counters with deeply integrated tool-using models and unparalleled access through widely used Microsoft products. However, questions remain about its long-term cost structure and the need to achieve comparable efficiencies. The ongoing push by OpenAI to explore massive data center projects like Stargate with SoftBank and Oracle, and its discussions with Microsoft about revised revenue share agreements, underscore the critical importance of compute costs to its future. The race for AI dominance will likely be defined not just by who has the smartest models, but by who can deliver that intelligence at the most sustainable price.
Reference Shelf:
The new AI calculus: Google’s 80% cost edge vs. OpenAI’s ecosystem
Google Succeeds With LLMs While Meta and OpenAI Stumble
Nvidia CEO: AI’s Next Frontier is Reasoning, Requiring “Hundred Times More Computing”