China Hacks the AI Math

Sign up for ARPU: Stay informed with our newsletter.
Programming note: ARPU will return next Friday with some thoughts on the hyperscalers' latest results.
Better Math for Worse Computers
In the software industry, you sometimes delay a product launch because you are trying to make it run better on the fastest computers in the world. DeepSeek just spent months delaying its flagship AI model so it could figure out how to run it on worse computers.
DeepSeek finally released its long-awaited V4 model last week. According to Bloomberg, the months-long delay was not a technical setback in the conventional sense. Instead, DeepSeek spent the better part of a year ripping up its software stack so that it could run on Huawei's Ascend chips. The company that famously built the R1 model in two months for under $6 million deliberately chose to spend the next year optimizing its codebase for hardware that is drastically less efficient than the American silicon it already had.
That is not a technology decision. That is a geopolitical favor. And it is the most revealing thing to happen in the AI race last month.
The Price of Parity
Before we look at the geopolitics, it is worth looking at the product, because V4 is a masterpiece of algorithmic frugality.
V4-Pro is a 1.6 trillion-parameter model that benchmarks competitively with the bleeding edge of American AI. It trails OpenAI's GPT 5.5 and Anthropic's Claude Opus 4.7 on most tests, but occasionally beats them on complex tasks like agentic web browsing. The performance gap is real, but it has narrowed to the point where the benchmark score is no longer the headline.
The price is the headline.
DeepSeek is currently running the equivalent of a Blue Light Special: V4-Pro is marked down to just $0.435 per million input tokens and $0.87 for output. For context, OpenAI charges $5 for input and $30 for output on GPT-5.5. That isn't a competitive price gap; it's a 96% discount.
How do they afford to do that? Because the underlying architecture is ruthlessly efficient. V4 supports a one-million-token context window — large enough to dump an entire codebase into a single prompt — while using roughly 90% less memory and only 27% of the compute its predecessor required for the exact same task.
V4 is not a shock on the scale of R1, but it doesn't need to win every benchmark to matter. It just needs to be "good enough" at a price point that makes you feel stupid for paying OpenAI. It is a serious model, priced by a company that has decided market share matters more than margin. And it forces a complete rethink of what premium, closed-source models are actually worth paying for.
The Shotgun Wedding
Here is the catch: V4 is DeepSeek's first model validated to run on Huawei's domestic chips. DeepSeek even noted that V4's prices could fall further once Huawei's new Ascend 950 supernodes ship at scale later this year. The company is explicitly tying its future profit-and-loss statement to the success of the Chinese state's hardware champion.
Nvidia CEO Jensen Huang put the stakes as plainly as anyone has. Speaking during an interview two weeks ago, just days before V4 launched, he said:
The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation. If future AI models are optimised in a very different way than the American tech stack, and as AI diffuses out into the rest of the world with Chinese standards and technology, China will become superior to the United States.
It is worth noting who is saying this. Huang runs the company that loses the most if DeepSeek's hardware pivot succeeds — and that has spent years lobbying Washington to let it sell more chips into China. His alarm is real, but it is not disinterested. What he is describing, stripped of the national framing, is a straightforward platform war: whichever hardware ecosystem the world's AI models are built on becomes the default, and defaults are hard to dislodge. Whether that outcome is "horrible" depends considerably on where you are standing.
If you look under the hood, though, DeepSeek's turn to Huawei is strictly limited to the easy stuff. MIT Technology Review reports that V4 still appears to use Nvidia chips for the heavy lifting of pre-training, while relegating the Huawei chips to inference (actually serving the answers to users). This makes sense. An earlier DeepSeek attempt to train exclusively on Huawei chips was reportedly derailed by yield problems, slow interconnects, and a generally miserable software stack. In other words, the last time DeepSeek tried to use these chips, it went so badly they quietly went back to Nvidia.
And yet, here we are. Beijing has been tapping Chinese AI labs on the shoulder, and strongly suggesting that it would be very patriotic to buy Huawei. DeepSeek is the leading lab in the country, which makes it the ultimate test case. If V4 inference works reliably on Ascend hardware at scale, China has proven it can build a parallel AI infrastructure stack. If it doesn't, DeepSeek will have lit months of its competitive lead on fire to do a favor for the government.
The Quarter-Trillion-Dollar Arbitrage
The V4 launch makes the most sense when you view it as the collision of two completely separate races.
On the model layer, China has reached a position that few predicted two years ago. Chinese models now account for 30% of global AI downloads, versus 15.7% for the United States — a lead in open-source distribution that is already settled.
And at the frontier, the gap has collapsed. The benchmark difference between the best American and Chinese models has compressed from somewhere between 17 and 31 percentage points in mid-2023 to just 2.7 percentage points today, according to the Stanford HAI 2026 AI Index. The U.S. still produces more top-tier closed models, and GPT-5.5 and Opus 4.7 still lead V4 on most direct comparisons. But the distance is now measured in single digits, not decades.
This is the context for the uncomfortable math that has the U.S. government so alarmed. Last year, the U.S. spent $285.9 billion on private AI investment; China spent $12.4 billion.† In most industries, a 23-to-1 spending advantage would buy a total monopoly. In AI, it appears to buy a 2.7 percentage-point lead on benchmarks.
This ROI gap is the subtext of the diplomatic friction we saw last week. The State Department sent a global cable — and the White House issued a memo — accusing Chinese labs of "industrial-scale distillation." This is the process of using the outputs of a massive, expensive frontier model to train a smaller, cheaper one.
To Washington, this looks like surreptitious espionage — an attempt to illicitly replicate the core capabilities of American research. To a cost-constrained AI lab, it looks like synthetic data training — a standard optimization technique used to make models more efficient.
The disagreement is essentially a collision between two different business models. The U.S. model is built on massive private capital and a "compute-maximalist" approach to research. The Chinese model, necessitated by capital and chip constraints, is built on extreme algorithmic efficiency.
The result is a peculiar kind of global arbitrage. The U.S. is effectively subsidizing the massive R&D costs of the global AI frontier, while other labs are finding ways to reach near-parity using a fraction of the budget. One side calls it innovation; the other calls it imitation. But from a purely financial perspective, it is simply a story of how a $12 billion budget managed to track a $285 billion one by treating the output of the frontier as a public resource.
The Hardware Ceiling
But you cannot arbitrage physics. And that is the second race.
On the hardware layer, the picture is the mirror image. The U.S. currently has approximately 39.7 million H100-equivalent chips. China has around 400,000.
That is a ratio of 100-to-1. Huawei's total aggregate AI computing power in 2025 will be roughly 5% of Nvidia’s, falling to 2% by 2027 as Nvidia scales faster. China is not catching up on silicon. It is being lapped.
This is the unstable equilibrium at the heart of AI geopolitics. China dominates the layer that produces the open-source models the world uses today. It is far behind on the layer that will determine who trains the models of tomorrow.
The U.S. export control strategy was premised on a simple equation: constrain the hardware, constrain the capability. That equation failed spectacularly at the software layer, because silicon starvation actually forced Chinese developers to write brilliantly efficient code. But as models grow exponentially larger, algorithmic efficiency has a ceiling. DeepSeek proved that you can do extraordinary things on a shoestring budget. It has not proven you can do them forever.
China has hacked the math. Now it has to figure out how to hack the physics. And as the engineers struggling with those Huawei chips will tell you, the physics are a lot less forgiving.
† Note: Total AI spending in China is likely higher than private figures suggest, due to the prevalence of government guidance funds.
📊 Data > Narrative
We pull key data points to show you the mathematical reality of what's happening in tech.
The Cloud Race Scorecard
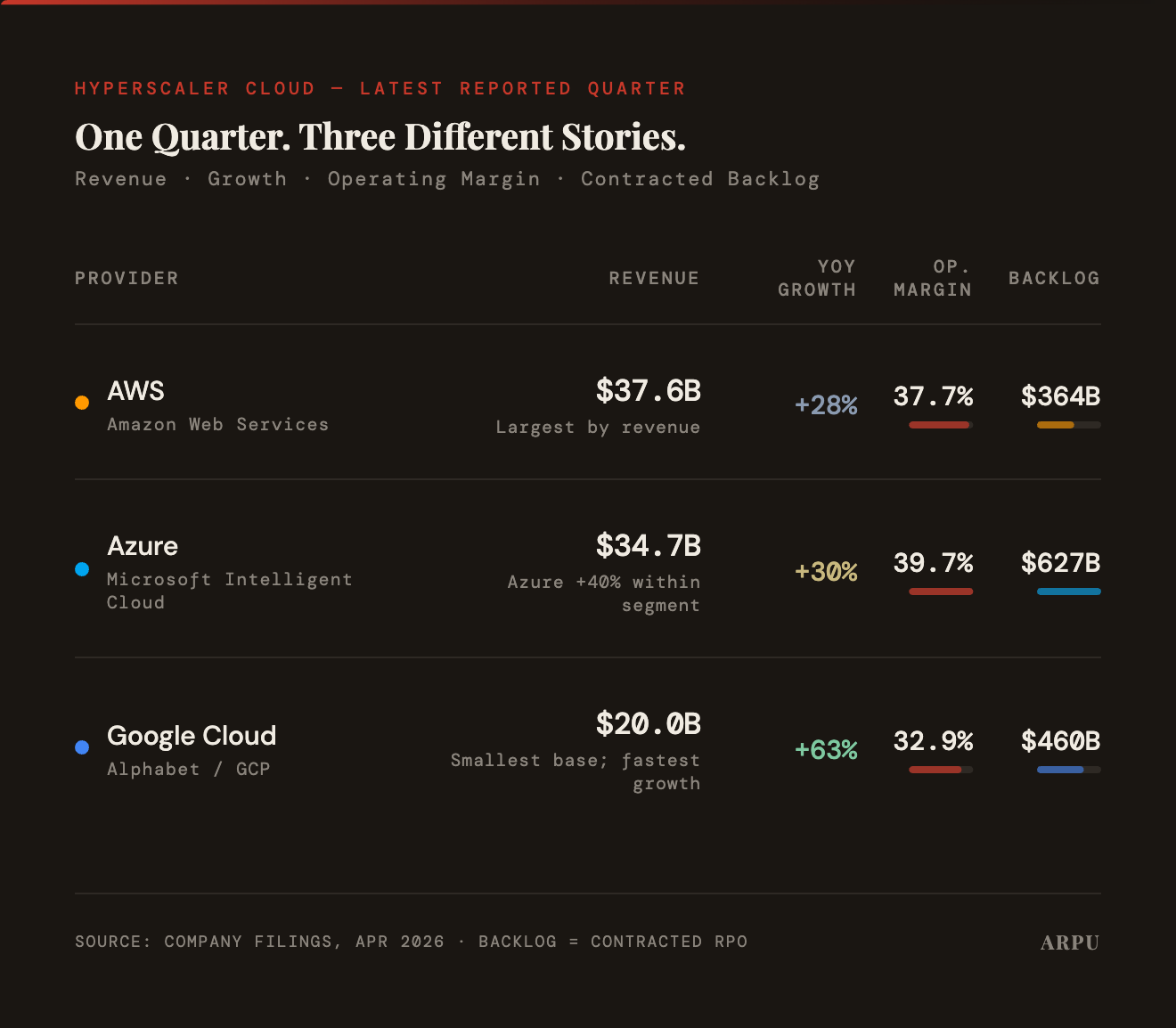
- The Data: The big three cloud providers all reported earnings this week. Google Cloud was the standout: revenue grew 63% year-on-year to $20 billion, the fastest growth rate of the three. AWS remains the largest by revenue at $37.6 billion (+28%), followed by Microsoft's Intelligent Cloud at $34.7 billion (+30%, with Azure specifically up 40%). Microsoft holds the largest contracted backlog at $627 billion, ahead of Google at $460 billion and AWS at $364 billion.
- The Takeaway: AWS is still the largest, and Microsoft carries the biggest backlog, but Google is growing fastest — and from a base small enough that it can sustain that pace for longer. The margin gap is narrowing too: Google Cloud's operating margin has expanded sharply over the past year. After years of playing catch-up on AI, Google had the best cloud quarter of the three. Whether that is a turning point or a data point is the question the next few quarters will answer.
You received this message because you are subscribed to ARPU newsletter. If a friend forwarded you this message, sign up here to get it in your inbox.