Google Just Sorted the Memory Trade

Sign up for ARPU: Stay informed with our newsletter - or upgrade to bespoke intelligence.
Programming note: we will return on Friday and take a look at Microsoft.
The Two-Class Memory Market
One of the peculiar features of an AI bubble is that investors eventually start buying nouns.
"Compute" works. "Power" works. "Memory" definitely works. Never mind that memory is less a single business than a loose collection of products, bottlenecks, and speculative adjacencies. Once the market decides a noun is central to the future, it tends to buy the whole category first and sort out the distinctions later, if at all.
That is what made Google's recent TurboQuant announcement so awkward. TurboQuant is a software technique that makes AI inference more memory-efficient. In plain English, it helps large language models do more work while using less memory and moving less data around. Google said it can reduce the memory required for one specific part of LLM inference by at least 6x.
The market's first response was the obvious one: if AI can be made meaningfully more efficient, then perhaps some of the memory demand investors had been happily projecting into the future is not as automatic as they thought. Memory stocks sold off. The initial pressure fell hardest on flash and storage names like Kioxia and Sandisk, whose AI story rested less on owning the bottleneck than on the assumption that enough spending on GPUs, servers, and data centers would eventually drag the rest of the memory complex higher with it.
That panic did not last very long. The rebound was broad. But the brief selloff still did something useful: it exposed the market's internal ranking of the memory trade.
The Memory Wall
The cleanest part of the story is HBM, or high-bandwidth memory. This is the premium memory stacked next to the GPU, feeding enormous amounts of data into AI accelerators fast enough to keep them useful. HBM is not just another chip category. It exists because ordinary memory is too slow for the job.
Here is IEEE Spectrum explaining the technical side of it:
Each HBM chip is made up of as many as 12 thinned-down DRAM chips called dies. Each die contains a number of vertical connections called through-silicon vias. The dies are piled atop each other and connected by arrays of microscopic solder balls aligned to the TSVs. This DRAM tower is then stacked atop what's called the base die, which shuttles bits between the memory dies and the processor.
The idea behind such a tight, highly connected squeeze with the GPU is to knock down what's called the memory wall. That's the barrier in energy and time of bringing the terabytes per second of data needed to run large language models into the GPU. Memory bandwidth is a key limiter to how fast LLMs can run.
In other words, HBM is not a nice-to-have accessory. It is the memory designed to keep the GPU from starving.
That is why TurboQuant does not really break the HBM story. However clever the software gets, frontier AI systems still need a great deal of data stored very close to the processor. This is why HBM remains the cleanest expression of the AI bottleneck trade.
The economics are equally rude. HBM costs roughly 3x as much as other memory and can account for 50% or more of the cost of a packaged AI GPU. Micron says HBM and other cloud-related products rose from 17% of its DRAM revenue in 2023 to nearly 50% in 2025, and it expects the HBM market to grow from $35 billion in 2025 to $100 billion by 2028.
This is not speculative adjacency. This is the toll booth.
The Spillover Trade
The flash and storage trade was built on a different kind of optimism.
HBM sits next to the GPU and helps the model run in real time. Flash memory and NAND do a different job: they store the data behind the system, inside SSDs and other infrastructure that hold model checkpoints, enterprise datasets, retrieval databases, and all the surrounding plumbing needed to serve AI at scale. The bull case was that if hyperscalers and enterprises were going to deploy AI everywhere, they would need not just more premium memory beside the chip, but more storage behind it too.
This was a very profitable theory. Sandisk rose more than 1,000% from August. Kioxia gained more than 600%. Investors were not just buying the memory AI cannot run without. They were also buying the memory that seemed likely to benefit if enough AI spending sloshed outward through the rest of the stack.
That is where TurboQuant became inconvenient. It did not make flash or NAND useless. It just reminded everyone that their AI upside depends on a longer chain of assumptions. If Google can reduce the memory footprint of inference, then some of the downstream demand investors were projecting into storage may turn out to be more compressible than expected.
HBM benefits from a direct architectural need. Flash and storage benefit from a broader proposition: that AI deployment at scale creates more demand throughout the system. That proposition may still prove correct. It is just less protected, and therefore more vulnerable to the sort of software breakthrough that causes analysts to rediscover nuance.
The Constraint That Still Matters
The reason the whole sector did not implode is that the broader memory market is still genuinely tight.
Data centers accounted for about 50% of global DRAM consumption in 2025, up from 32% five years earlier. Big Tech is on track to spend roughly $650 billion in 2026, around 80% above last year's record, to keep expanding AI infrastructure. DRAM prices rose 80% to 90% in the quarter IEEE Spectrum examined, because AI demand was diverting supply away from the rest of the electronics market.
Intel CEO Lip-Bu Tan had the most useful summary of the situation: "There's no relief until 2028."
That is not just an AI-server story. It is now everybody else's margin problem. HP says memory accounts for roughly 35% of a laptop's bill of materials, up from about 15% to 18% just a quarter earlier. Dell has raised prices on servers and PCs. Industry analysts estimate higher memory costs could raise smartphone bill-of-materials costs by 15% or more. IDC projects the global smartphone market could shrink 12.9% in 2026, which would be the sharpest drop on record.
So even if TurboQuant changes part of the inference math, it does not erase the larger fact that AI is still consuming so much memory infrastructure that the sector remains supply-constrained. The software got smarter. The shortage did not disappear.
The Rude Question
What Google changed was not AI demand itself. It changed the market's willingness, however briefly, to pretend that all memory demand scales in the same way.
For a while, "memory" was a perfectly adequate AI trade. TurboQuant did not kill that trade. It merely forced investors to remember that some memory solves an immediate physical bottleneck, while some memory benefits because it happens to live downstream from a spending boom.
Of course, that is not the end of the story for flash, storage, or the broader memory complex. It is just the end of a slightly lazier version of the story.
First the market buys the noun. Then it discovers there are classes within it.
📊 Data > Narrative
We pull key data points to show you the mathematical reality of what's happening in tech. Monitor the industry vitals here.
The Memory Market Is Not One Market
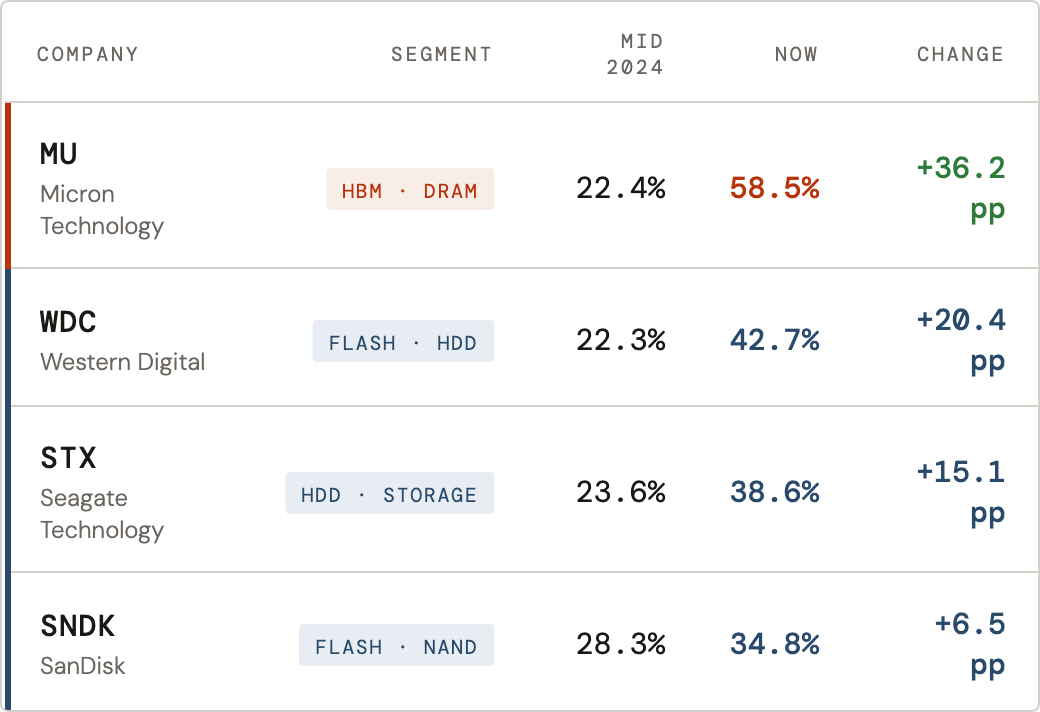
- The Data: Micron's gross margin has expanded by 36 percentage points since mid-2024, reaching 58.5% — nearly matching software-level profitability. Flash and storage players (SNDK, STX, WDC) gained between 6 and 20 points over the same period, finishing well below 45%.
- The Takeaway: Margins don't lie. The profitability data shows two very different businesses. Micron owns the physical bottleneck — HBM has no software substitute. The rest of the complex is benefiting from a spending boom, which is still a fine place to be.
P.S. This week's Tech Sector Diagnostics (Semiconductor) is out. One number worth pausing on: NVIDIA's P/E ratio is currently in the bottom 2% of its own 2-year history — historically cheap on its own terms, even as its operating margins remain strong. The full one-page snapshot, covering 24 semiconductor names on operational performance vs. valuation, is here.
You received this message because you are subscribed to ARPU newsletter. If a friend forwarded you this message, sign up here to get it in your inbox.